Waarom je USB-stick van 300MB/s na 20 seconden trager wordt
Er is een moment dat bijna iedereen met een moderne USB-stick wel eens meemaakt, waarop de werkelijkheid ineens het marketingverhaal onderbreekt.
Je sluit een splinternieuwe USB-stick aan. De verpakking belooft razendsnelle prestaties. Misschien zegt de website dat hij 300MB/s kan schrijven. Misschien liet een reviewer benchmark-screenshots zien die bewijzen hoe snel hij is. Alles ziet er indrukwekkend uit.
Daarna kopieer je een grote map naar de stick.
In het begin schiet de overdracht vooruit, precies zoals beloofd. De voortgangsbalk vliegt. Windows meldt ongelooflijke schrijfsnelheden. Je begint bijna te denken dat opslagtechnologie eindelijk zover is dat kleine USB-sticks zich gedragen als mini-supercomputers.
Dan gebeurt er iets vreemds.
De snelheid stort in.
Wat begon met 300MB/s wordt ineens 80MB/s. Daarna 45MB/s. Soms zelfs nog lager. De voortgangsbalk kruipt vooruit en nu staar je naar “18 minuten resterend”, terwijl je je afvraagt wat er is gebeurd met de wonderstick die je net hebt gekocht.
In ons eerdere artikel, Waarom je elke “beste USB-stick”-lijst eigenlijk moet negeren, hadden we het erover dat de meeste USB-benchmarkartikelen zich sterk richten op korte pieksnelheden, terwijl ze het diepere gedrag van het apparaat zelf negeren. Dat artikel was het bredere argument. Dit artikel is de technische uitleg daaronder.
Want zodra je begrijpt hoe BOT en UASP werken, hoe NAND-cache zich gedraagt en hoe moderne USB-controllers langdurige schrijfacties beheren, zie je sneller waarom veel claims van “300MB/s” maar een deel van het verhaal vertellen.
Pieksnelheid en aanhoudende snelheid zijn niet hetzelfde
De meeste USB-sticks gebruiken tegenwoordig een vorm van cache om het eerste deel van een schrijfactie veel sneller te laten lijken dan de stick tijdens een lange overdracht werkelijk kan volhouden.
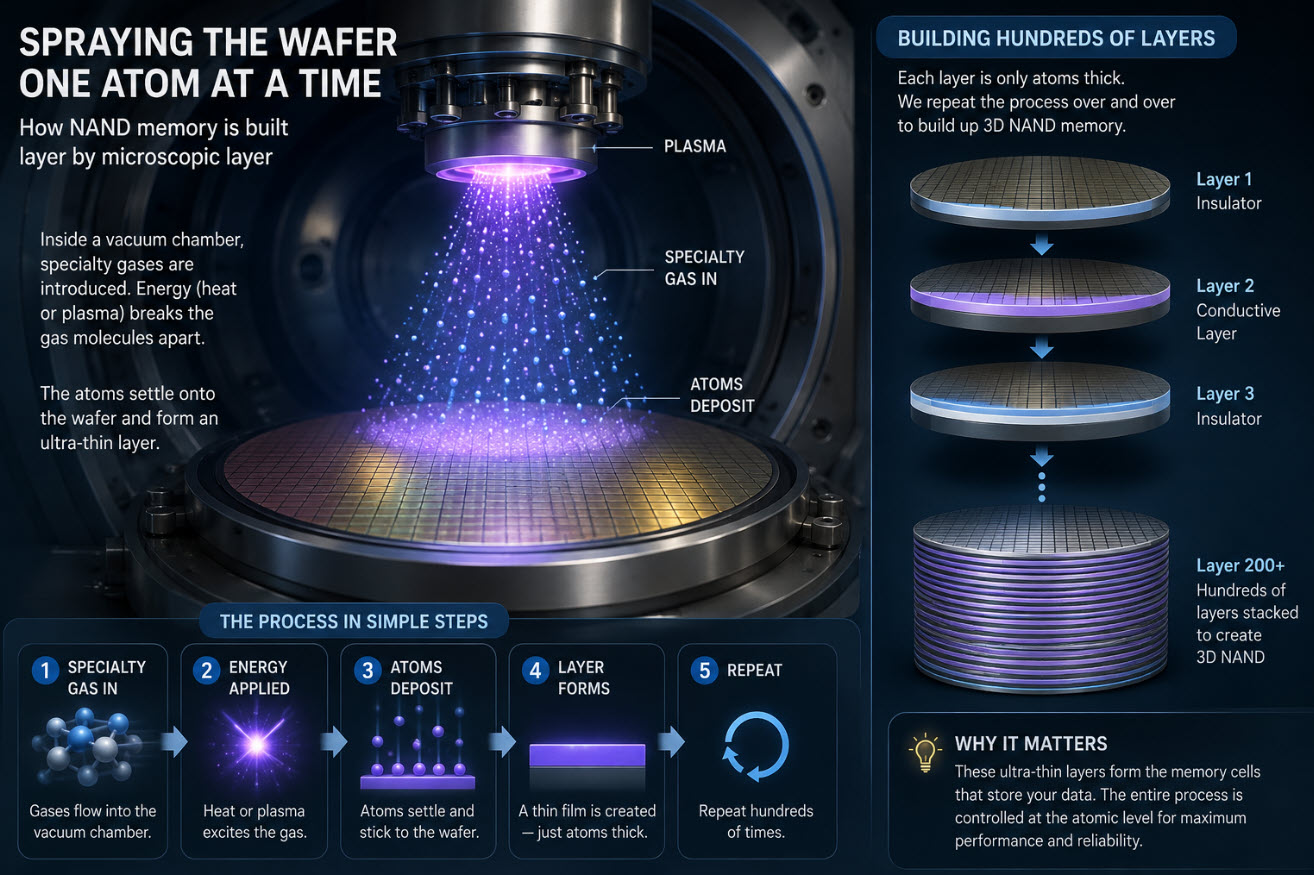
Moderne NAND-flashgeheugen is vaak gebaseerd op TLC- of QLC-technologie. Die geheugentypen zijn uitstekend voor capaciteit en kosten, maar ze zijn niet altijd geweldig in het continu schrijven van grote hoeveelheden data. Om die beperking te omzeilen gebruiken veel sticks een tijdelijk hogesnelheidsgebied dat vaak pseudo-SLC-cache wordt genoemd.
Denk aan die cache als de balie vooraan in een druk verzendkantoor. In het begin worden pakketten snel op de balie gezet en voelt alles vlot. Maar als de achterkamer die pakketten niet in hetzelfde tempo kan verwerken, raakt de balie uiteindelijk vol. Zodra dat gebeurt, vertraagt de hele operatie tot de snelheid van de achterkamer.
Dat is wat er in veel USB-sticks gebeurt. Het eerste deel van de overdracht gaat naar snelle cache. Zodra de cache vol raakt, moet de controller rechtstreeks naar langzamere NAND schrijven of beginnen met het wegschrijven van gecachte data naar langetermijnopslag, terwijl er nog steeds nieuwe data vanaf de computer binnenkomt.
Op dat moment verschijnt de echte aanhoudende schrijfsnelheid.
Het USB-protocol speelt ook een rol
Nu voegen we nog een laag toe, want het flashgeheugen is niet het enige dat de prestaties bepaalt.
Ook de manier waarop het USB-apparaat met de computer communiceert is belangrijk. Twee veelgebruikte transportmethoden zijn BOT en UASP. De namen klinken niet bepaald vriendelijk, maar het verschil is belangrijk.
BOT staat voor Bulk-Only Transport. Het is de oudere methode die door veel traditionele USB-sticks wordt gebruikt. BOT werkt heel rechttoe rechtaan: de computer stuurt één opdracht, wacht tot die opdracht klaar is en stuurt daarna de volgende opdracht.
Dat is eenvoudig en compatibel, maar niet bijzonder efficiënt.
UASP staat voor USB Attached SCSI Protocol. UASP is nieuwer en efficiënter omdat het command queuing en parallelle opdrachtverwerking ondersteunt. In plaats van te wachten tot één taak volledig klaar is voordat de volgende begint, houdt UASP de opslagpijplijn veel soepeler in beweging.
Als BOT een eenbaansweg met stopborden is, dan lijkt UASP meer op een meerbaansweg met betere doorstroming. Beide wegen kunnen naar dezelfde bestemming leiden, maar de ene verspilt minder tijd tussen bewegingen.
BOT kan prestaties afremmen
Met BOT besteedt het opslagapparaat meer tijd aan wachten tussen opdrachten. Die extra wachttijd maakt misschien niet veel uit voor een goedkope USB 2.0-stick die kleine bestanden verplaatst, maar wordt duidelijker zichtbaar zodra het opslagmedium sneller wordt.
Dat geldt vooral bij gemengde workloads, willekeurige bestandsoverdrachten en grotere langdurige bewerkingen waarbij de controller veel verzoeken efficiënt moet beheren. BOT kan niet bijzonder goed omgaan met dat soort verkeer, omdat het is gebouwd voor een oudere opslagwereld.
Dat betekent niet dat BOT kapot is. Het betekent simpelweg dat BOT beperkt is. Het werkt, maar het is niet de meest efficiënte manier om data door een modern USB-opslagapparaat met hoge snelheid te verplaatsen.
UASP helpt, maar lost niet alles op
UASP verbetert de communicat kant van het verhaal. Het verlaagt de latency, ondersteunt betere opdrachtverwerking en kan de overhead tussen de computer en het opslagapparaat verminderen. Dat is een van de redenen waarom veel externe USB-SSD’s veel sneller en soepeler aanvoelen dan gewone USB-sticks.
Maar UASP is geen magie.
Als de NAND in de stick traag is, als de controller zwak is, als de cache klein is of als het apparaat snel oververhit raakt, kan UASP die hardware niet veranderen in iets wat het niet is.
Een beter transportprotocol helpt data efficiënter bij de controller te komen. Het verandert niet de fysieke grenzen van het NAND-geheugen zodra de controller de data echt moet wegschrijven.
Dat is het subtiele punt dat veel snelheidsclaims missen. Een stick kan een snelle interface ondersteunen en toch slecht gedrag vertonen bij aanhoudend schrijven nadat de cache is uitgeput.
Waarom de eerste 20 seconden misleidend kunnen zijn
Een korte benchmark laat de stick vaak op zijn best mogelijke moment zien. De stick is leeg. De cache is beschikbaar. De controller is koel. Garbage collection is nog niet agressief geworden. De test gebruikt misschien grote sequentiële blokken waardoor het apparaat schoon en efficiënt lijkt.
Dat is niet hetzelfde als het kopiëren van 80GB aan videobestanden, een map vol gemengde documenten of een compleet software-image naar de stick.
Tijdens een lange overdracht gebeuren er meerdere dingen tegelijk. De cache raakt vol. De controller begint data intern opnieuw te organiseren. De schrijfsnelheid van de NAND wordt de echte limiet. Warmte kan zich opbouwen. Firmwarebeslissingen worden zichtbaarder. Als de stick is gebouwd rond lage kosten in plaats van aanhoudende prestaties, wordt de daling duidelijk.
Daarom kan een “300MB/s”-USB-stick die snelheid technisch gezien halen en zich tijdens een echte workload toch niet gedragen als een stick van 300MB/s.
Waarom dit belangrijker is dan benchmark-screenshots
Voor casual gebruik is het verschil misschien alleen irritant. Iemand kopieert vakantiefoto’s of een paar PDF’s, wacht wat langer en gaat verder.
In professionele omgevingen telt het verschil zwaarder. Als je USB-sticks dupliceert, software distribueert, media voor veldupdates voorbereidt, data registreert of grote imagebestanden verplaatst, wordt de aanhoudende schrijfsnelheid de echte maatstaf van het apparaat.
Een stick die indrukwekkend lijkt in een korte benchmark kan slecht presteren wanneer hij dezelfde schrijfactie honderden keren moet herhalen. Daar worden zwakke NAND, kleine cache, slecht controllerontwerp en thermische beperkingen onmogelijk om te verbergen.
Dit is ook waarom professionele USB-workflows meestal kijken naar het volledige gedrag van het apparaat, niet alleen naar het getal op de verpakking. Snelheid is een deel van het verhaal, maar niet het hele verhaal.
De betere vraag om te stellen
De betere vraag is niet simpelweg: “Hoe snel is deze USB-stick?”
De betere vraag is: “Hoe lang kan deze USB-stick die snelheid vasthouden?”
Die ene verandering in formulering verplaatst de discussie van marketing naar engineering. Het dwingt je na te denken over NAND-type, controllerontwerp, cachegrootte, thermisch gedrag, transportprotocol, firmwarekwaliteit en de workload die wordt getest.
Pieksnelheid laat zien wat de stick onder makkelijke omstandigheden kan doen. Aanhoudende snelheid laat zien waar de stick werkelijk van gemaakt is.
Is het je opgevallen?
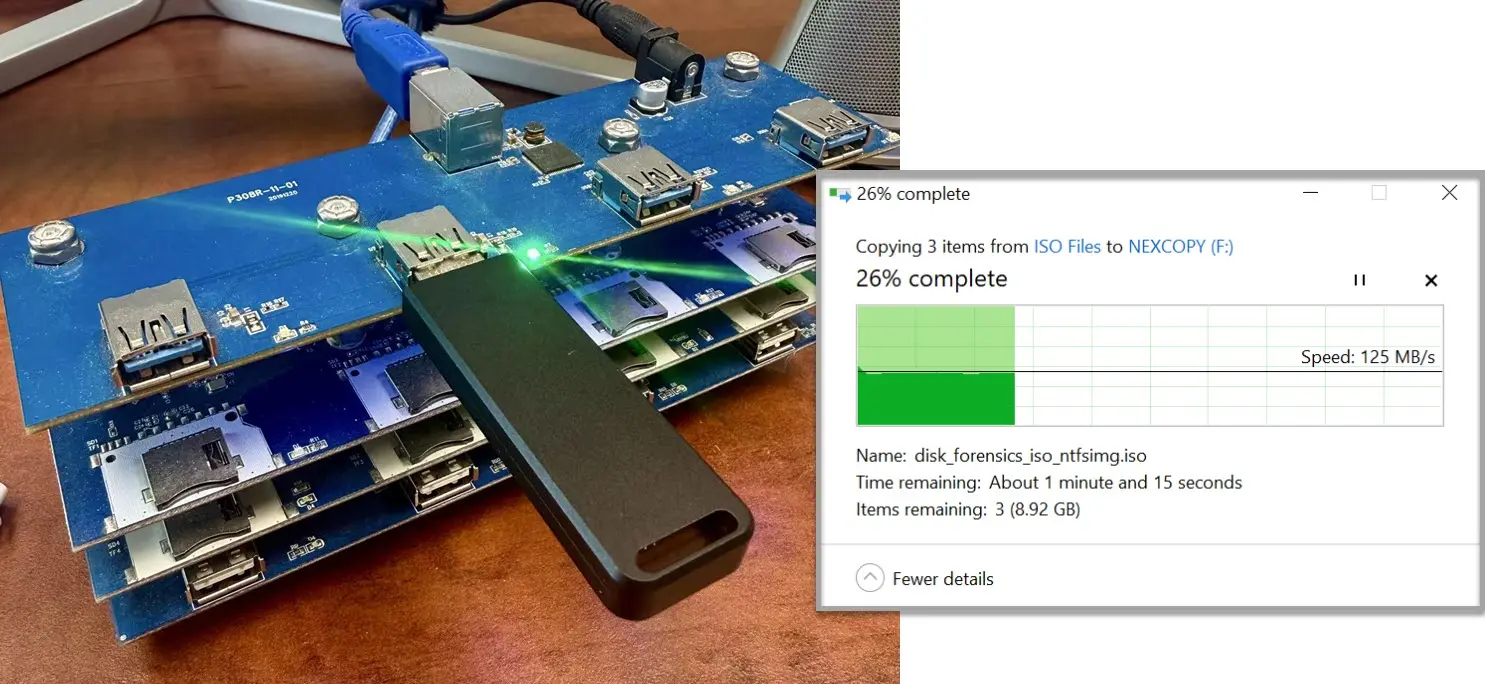
De afbeelding die voor dit artikel is gebruikt, bewijst stilletjes het hele punt.
De verpakking van de USB-stick adverteert schrijfsnelheden tot 400MB/s, terwijl de daadwerkelijke aanhoudende overdracht die tijdens het kopiëren van een groot bestand wordt getoond dichter bij 125MB/s ligt. Dat verschil is niet per se fraude of valse reclame. Het is de kloof tussen piekprestaties en aanhoudend gedrag in de echte wereld.
USB-stickmarketing leunt nog steeds zwaar op eenvoudige snelheidsgetallen, omdat eenvoudige getallen makkelijk te drukken, makkelijk te vergelijken en makkelijk te verkopen zijn.
Maar echte USB-prestaties zijn gelaagder dan dat.
BOT versus UASP doet ertoe. Cachegedrag doet ertoe. NAND-kwaliteit doet ertoe. Controllerontwerp doet ertoe. Testen op aanhoudende schrijfsnelheid doet ertoe. Voor meer context hierover kun je ook ons artikel lezen over waarom sommige USB-apparaten BOT gebruiken en andere UASP.
Zodra je die lagen begrijpt, begint één claim van “300MB/s” minder op een definitief antwoord te lijken en meer op het begin van een betere vraag.
Want bij moderne USB-opslag zit het echte verschil tussen producten niet altijd in hoe snel ze tien seconden lang presteren. Het zit in hoe intelligent ze zich gedragen zodra de makkelijke omstandigheden verdwijnen.
Redactionele opmerking & EEAT-toelichting: Dit artikel is geschreven als een educatief technisch redactioneel stuk op basis van echt USB-opslaggedrag, kennis van controllerarchitectuur en analyse van aanhoudende overdrachten zoals die worden waargenomen in professionele duplicatie- en implementatieomgevingen. De bespreking weerspiegelt praktische branche-ervaring met USB-flashgeheugen, configuratie op controllerniveau, workflows voor schrijfbeveiliging en methoden voor prestatievalidatie die in productieomgevingen worden gebruikt.
AI-ondersteunde redactionele tools zijn gebruikt om de tekst te helpen organiseren, verfijnen en leesbaarder te maken, terwijl de technische richting, inhoudelijke beoordeling, conclusies en analyse uit de praktijk zijn geleid en gecontroleerd door een menselijke redacteur met langdurige ervaring in USB-opslagtechnologieën en flashgeheugenworkflows.
De hoofdafbeelding in dit artikel is speciaal gemaakt om het verschil te laten zien tussen geadverteerde piekschrijfsnelheden en werkelijk aanhoudend overdrachtsgedrag tijdens bewerkingen met grote bestanden.