Waarom AI rekenkracht dichter bij opslag brengt
Als je de eerdere delen in deze serie hebt gevolgd, heb je waarschijnlijk gemerkt dat er langzaam een patroon zichtbaar wordt.
In het eerste artikel bespraken we hoe NAND-flash niet verdwijnt, maar juist onderdeel wordt van een veel grotere AI-geheugenhiërarchie. Daarna keken we naar High Bandwidth Memory (HBM) en waarom moderne GPU’s afhankelijk zijn van data die fysiek dichter bij de processor staat. Vervolgens gingen we verder met Storage Class Memory, High Bandwidth Flash, de beperkingen van DRAM-schaalbaarheid en uiteindelijk waarom zelfs traditionele harde schijven nog steeds belangrijk blijven, omdat AI-infrastructuur op een schaal werkt die de meeste mensen behoorlijk onderschatten.
Op het eerste gezicht lijken dat misschien losse onderwerpen.
Dat zijn ze niet.
Ze zijn allemaal symptomen van dezelfde onderliggende druk: AI-systemen worstelen niet langer vooral met rekenkracht. Ze worstelen met hoe efficiënt ze data kunnen verplaatsen.
Die verschuiving verandert bijna alles aan de manier waarop infrastructuur wordt ontworpen.
Decennialang volgde computing een vrij stabiel model. Opslag bewaarde de data, geheugen zette die klaar en processors haalden op wat ze nodig hadden. Naarmate processors sneller werden, probeerde het systeem ze simpelweg efficiënter te voeden met betere bussen, grotere caches en snellere geheugentechnologieën.
AI heeft de schaal van het probleem veranderd.
Moderne GPU-clusters kunnen informatie met zo’n enorme snelheid verwerken dat het verplaatsen van data binnen het systeem zelf een van de grootste knelpunten in de hele architectuur is geworden. In sommige omgevingen is de processor zelf niet langer het trage onderdeel. De vertraging ontstaat doordat de juiste data niet snel en consistent genoeg bij de processor komt om die volledig bezig te houden.
Dat besef duwt de industrie stilletjes in een nieuwe richting.
In plaats van steeds grotere hoeveelheden data voortdurend heen en weer door het systeem te sturen, begint AI-infrastructuur delen van de rekenkracht dichter te plaatsen bij waar de data al staat.
En zodra je begrijpt waarom dat gebeurt, beginnen veel van de eerdere artikelen in deze serie veel duidelijker in elkaar te passen.
AI begint tegen een muur van dataverplaatsing aan te lopen
Een van de belangrijkste ideeën uit het eerdere HBM-artikel was dat moderne AI-systemen vaak niet vertragen omdat de processor te weinig rekenvermogen heeft, maar omdat het systeem de data niet snel genoeg kan aanleveren om de processor bezig te houden.
Dat probleem wordt veel serieuzer zodra AI-workloads zich uitbreiden over volledige racks en clusters.
Een moderne AI-accelerator kan verbazingwekkende hoeveelheden informatie parallel verwerken. Het probleem is dat datasets niet langer klein genoeg zijn om volledig binnen de snelste geheugenlagen te passen. Zelfs met HBM en grote hoeveelheden DRAM moeten enorme datavolumes nog steeds reizen via interconnects, bussen, fabrics, opslaglagen en netwerkinfrastructuur.
Die beweging heeft een prijs.
Dat zie je terug als latency, maar dat is slechts een deel van het verhaal. Je ziet het ook terug als stroomverbruik, warmte, koelbehoefte, congestie, synchronisatievertragingen en stilstaande rekencycli. Zoals we in het DRAM-deel bespraken, worden zelfs kleine vertragingen verrassend duur zodra duizenden GPU’s tegelijk aan het werk zijn. Een korte pauze vermenigvuldigd over een groot AI-cluster kan een enorme hoeveelheid verloren benutting betekenen.
Dat verandert de technische prioriteiten.
Jarenlang werd infrastructuur grotendeels ontworpen rond het maximaliseren van rekenprestaties. AI-systemen dwingen engineers nu om minstens zo zwaar na te denken over datalokaliteit, dus waar informatie fysiek staat ten opzichte van de processor die die informatie probeert te gebruiken.
Simpel gezegd: afstand doet er nu veel meer toe dan vroeger.
GPU’s werden zo snel dat de rest van het systeem begon achter te lopen
Een van de vreemde dingen aan AI-infrastructuur is dat vooruitgang op één gebied vaak zwakke plekken ergens anders blootlegt.
Naarmate GPU’s sneller werden, werd geheugenbandbreedte het knelpunt. Dat leidde tot HBM. Toen de capaciteitsbeperkingen van HBM duidelijker werden, begon de industrie tussenlagen zoals Storage Class Memory te introduceren. Toen DRAM-schaalbaarheid duurder en fysiek lastiger werd, begonnen systemen zwaarder op NAND te leunen, terwijl tegelijk concepten zoals High Bandwidth Flash werden onderzocht.
En terwijl AI-datasets bleven groeien richting petabytes en exabytes, bleven harde schijven stilletjes essentieel, omdat de economie van het opslaan van zoveel informatie simpelweg niet op een andere manier kon werken.
Elk artikel in deze serie wees eigenlijk vanuit een andere hoek naar dezelfde conclusie.
De oude aanname dat rekenkracht hier zit en opslag daar, begint uit elkaar te vallen. De reden is vrij eenvoudig: GPU’s kunnen data tegenwoordig sneller verwerken dan traditionele architecturen die data comfortabel kunnen aanleveren.
Dat zorgt voor een situatie waarin enorme hoeveelheden systeemactiviteit simpelweg worden besteed aan het vervoeren van informatie van de ene plek naar de andere. In praktische termen beginnen sommige AI-omgevingen minder op pure rekenproblemen te lijken en meer op logistieke problemen.
De industrie begon een andere vraag te stellen
Lange tijd richtte innovatie in opslag zich vooral op het sneller maken van opslagapparaten. Snellere SSD’s, snellere interfaces, snellere NAND en snellere controllers deden er allemaal toe, en dat doen ze vandaag nog steeds.
Maar AI-workloads begonnen een dieper probleem daaronder bloot te leggen.
Op een gegeven moment begonnen engineers te beseffen dat het probleem niet altijd de snelheid van het opslagapparaat zelf was. Het probleem was het herhaaldelijk heen en weer verplaatsen van enorme hoeveelheden data door het hele systeem.
Dat subtiele onderscheid is belangrijk, want zodra het probleem dataverplaatsing wordt in plaats van eenvoudige opslagsnelheid, begint de oplossing ook te veranderen.
In plaats van eindeloos te vragen hoe opslag sneller kan worden gemaakt, begon de industrie te vragen hoe ver de data überhaupt moet reizen.
Die vraag beïnvloedt nu bijna elk onderdeel van modern AI-infrastructuurontwerp.
Rekenkracht dichter brengen bij waar de data al staat
Hier begint de architectuur te verschuiven.
In plaats van opslag te behandelen als een volledig passieve laag die alleen maar op verzoeken wacht, beginnen nieuwere systemen bepaalde taken dichter bij de data zelf uit te voeren. Niet per se volledige GPU-verwerking, maar lokale bewerkingen die onnodige verplaatsing door de rest van het systeem verminderen.
Sommige systemen voeren nu filtering, indexering, zoekbewerkingen, compressie, voorbereiding voor ophalen en dataorganisatie dichter bij de opslaglaag uit, voordat de informatie ooit de primaire rekenmachines bereikt.
Het doel is niet om GPU’s te elimineren of snel geheugen te vervangen. Het doel is verspilling verminderen.
Als het systeem kan voorkomen dat enorme hoeveelheden onnodige data door de infrastructuur worden vervoerd, wordt het hele platform efficiënter. Dit is een van de redenen waarom de grens tussen rekenkracht en opslag begint te vervagen.
Opslag gedraagt zich niet langer als een volledig inactieve bestemming onderaan de hiërarchie. Het wordt actiever betrokken bij hoe data wordt voorbereid, klaargezet, gefilterd en stroomopwaarts wordt aangeleverd.
Als je terugdenkt aan het eerdere artikel over High Bandwidth Flash, is deze richting heel logisch. Dat artikel liet zien hoe NAND zelf richting meer geheugengedrag werd geduwd. Dit artikel trekt hetzelfde idee nog een stap verder door te laten zien hoe de omliggende architectuur zich ook aanpast rond de kosten van dataverplaatsing.
De magazijnanalogie begint er anders uit te zien
De magazijnanalogie die we in deze serie hebben gebruikt, werkt hier nog steeds, maar het magazijn zelf is gaan veranderen omdat de workload binnen dat magazijn is veranderd.
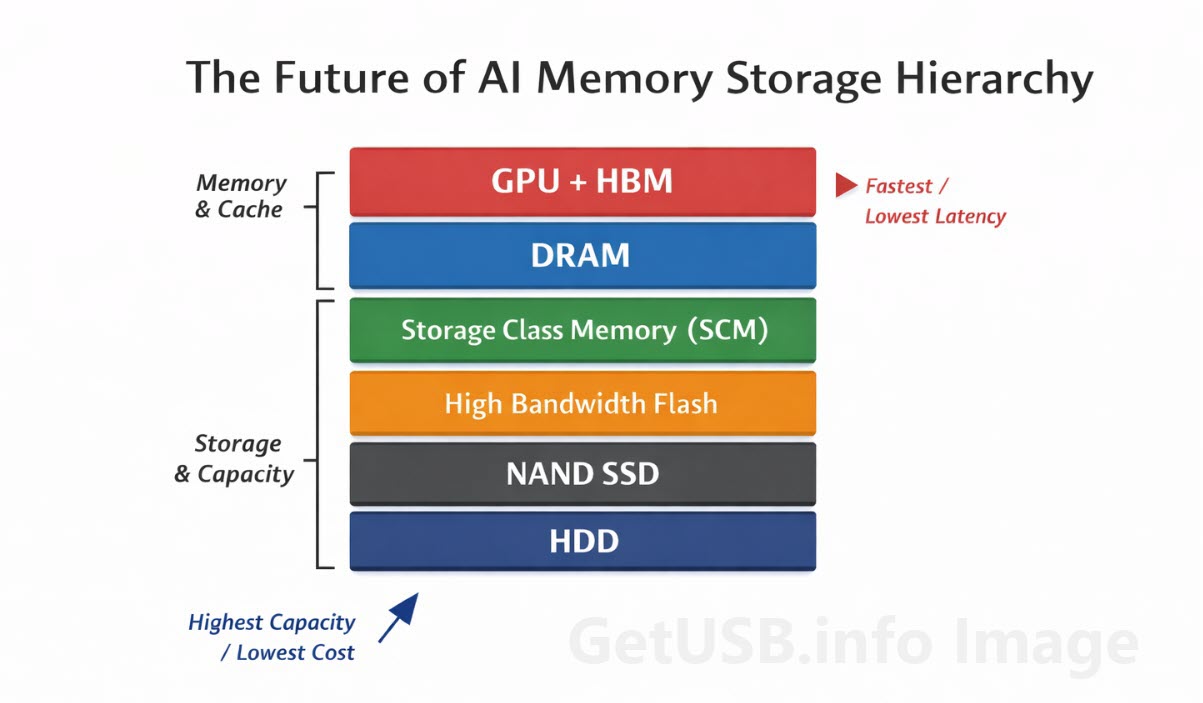
In de eerdere delen was de indeling vrij overzichtelijk. HBM stelde het laadperron voor waar de volgende pallet al klaarstond naast de werknemers. DRAM was de actieve werkvloer waar het directe sorteren en verwerken plaatsvond. Storage Class Memory werd de voorbereidingsruimte net achter het laadperron, terwijl NAND de hoofdstellingen verder achterin het magazijn vertegenwoordigde. Harde schijven verzorgden de diepere bulkopslag waar langetermijnvoorraad stond, omdat capaciteit belangrijker was dan directe toegangssnelheid.
Dat model blijft in grote lijnen overeind, maar AI-systemen beginnen inefficiënties bloot te leggen in hoeveel beweging er tussen die gebieden plaatsvindt.
Stel je een magazijn voor waar werknemers meer tijd kwijt zijn aan het heen en weer rijden met heftrucks door het gebouw dan aan het daadwerkelijk verwerken van voorraad. Eerst reageert het management door snellere heftrucks te kopen, de gangpaden breder te maken en de laadperrons te verbeteren. Die upgrades helpen een tijdje, maar uiteindelijk bereikt de operatie een punt waarop het transport zelf het probleem wordt. De vertragingen worden niet langer veroorzaakt door trage werknemers of onvoldoende apparatuur. De vertragingen komen door de enorme hoeveelheid beweging die nodig is om de workflow draaiende te houden.
Dat is steeds vaker waar grote AI-systemen tegenaan lopen.
Het probleem is niet meer alleen hoe snel data kan worden verwerkt zodra die bij de GPU aankomt. Het probleem is hoeveel infrastructuurinspanning wordt besteed aan het steeds opnieuw vervoeren van die data door het systeem.
Dus in plaats van transport eindeloos te optimaliseren, begint de indeling te veranderen. Kleine werkstations verschijnen dichter bij de stellingen zelf. Bepaalde sorteertaken gebeuren lokaal. Filtering gebeurt lokaal. Datavoorbereiding begint dichter plaats te vinden bij waar de informatie al staat, waardoor het systeem minder vaak enorme hoeveelheden materiaal heen en weer door de volledige operatie hoeft te verplaatsen.
Die verschuiving is in feite wat AI-infrastructuur op architectuurniveau begint te doen. Het doel is niet om opslag in een processor te veranderen of centrale rekenkracht volledig te elimineren. Het doel is onnodige beweging verminderen, omdat op AI-schaal zelfs kleine inefficiënties verrassend duur worden zodra ze worden vermenigvuldigd over duizenden accelerators die tegelijk draaien.
AI-infrastructuur wordt uit noodzaak meer gedistribueerd
Een van de interessantere gevolgen van deze verschuiving is dat AI-infrastructuur veel meer gedistribueerd begint te worden dan traditionele computeromgevingen ooit nodig hadden.
Oudere architecturen gingen ervan uit dat het belangrijkste werk vooral op centrale rekenlocaties zou plaatsvinden, terwijl opslag grotendeels passief bleef en gescheiden was van de verwerkingslaag. Dat model werkte decennialang redelijk goed, omdat de hoeveelheid data die door het systeem bewoog nog beheersbaar was ten opzichte van de snelheid van de processors die die data verbruikten.
AI verandert de schaal van de vergelijking volledig.
De hoeveelheid informatie die wordt verwerkt, opnieuw bekeken, klaargezet, gecachet, geïndexeerd en opgehaald is nu zo groot dat centrale verplaatsing zelf inefficiënties begint te veroorzaken. In plaats van dat rekenkracht simpelweg naar beneden reikt in opslag wanneer er iets nodig is, proberen systemen nuttige data steeds vaker dichter te positioneren bij waar die waarschijnlijk als volgende wordt gebruikt.
Dat is een deel van de reden waarom technologieën zoals vectordatabases, gedistribueerde inferentiesystemen, retrieval-lagen, lokale caching en near-data processing zoveel aandacht beginnen te krijgen. Op het eerste gezicht lijken dit misschien losse technologieën die niet-gerelateerde problemen oplossen, maar daaronder reageren ze allemaal op dezelfde druk. De industrie probeert te verminderen hoe vaak enorme hoeveelheden informatie lange afstanden door de infrastructuur moeten afleggen voordat zinvol werk kan beginnen.
Zoals je waarschijnlijk in deze serie hebt gemerkt, wordt de geheugenhiërarchie zelf geleidelijk minder rigide dan vroeger. De nette scheiding tussen “rekenkracht hier” en “opslag daar” begint zachter te worden, omdat AI-workloads systemen belonen die data fysiek dichter houden bij waar verwerking plaatsvindt.
Die trend zal waarschijnlijk doorgaan, omdat de economie van grootschalige AI steeds meer efficiëntie in verplaatsing beloont, net zo goed als ruwe rekenkracht.
De geheugenhiërarchie begint in elkaar over te lopen
Een van de stillere thema’s onder elk deel van deze serie is de geleidelijke erosie van de oude grenzen tussen geheugen, opslag en rekenkracht.
In het HBM-artikel keken we naar hoe geheugen fysiek dichter bij de processor zelf werd geplaatst, omdat zelfs traditionele DRAM-plaatsing vertragingen begon te veroorzaken die op AI-schaal groot genoeg waren om ertoe te doen. In het deel over Storage Class Memory verschoof de aandacht naar het verminderen van de scherpe overgang tussen snel geheugen en tragere persistente opslag. High Bandwidth Flash duwde NAND naar een actievere rol binnen het werkende datapad, terwijl het DRAM-artikel liet zien waarom het simpelweg eindeloos opschalen van traditioneel geheugen zowel economisch als fysiek moeilijk wordt.
Nu duwt dit artikel diezelfde ontwikkeling nog een stap verder door te laten zien hoe de architectuur zelf zich aanpast rond de kosten van dataverplaatsing.
Wat dit bijzonder interessant maakt, is dat geen van deze technologieën elkaar echt vervangt. De industrie heeft NAND niet opgegeven toen HBM arriveerde. Ze heeft DRAM niet vervangen alleen omdat Storage Class Memory verscheen. Ook harde schijven blijven diep relevant, ondanks decennia aan voorspellingen dat solid-state opslag ze volledig zou wegvagen.
In plaats daarvan wordt het systeem gelaagder, gespecialiseerder en bewuster van waar data fysiek bestaat ten opzichte van de rekenmiddelen die die data proberen te gebruiken.
Dat onderscheid is belangrijk, omdat het verandert hoe we over de toekomst van AI-infrastructuur moeten nadenken. De evolutie gebeurt niet omdat één doorbraaktechnologie plotseling alles heeft opgelost. De evolutie gebeurt omdat de workload zelf de industrie dwong om opnieuw te organiseren hoe elke laag meedoet aan het efficiënt voeden van informatie richting de rekenkant.
Als je een stap terug doet en naar het grotere geheel kijkt, wordt het patroon veel makkelijker te zien. Elke grote verschuiving die we in deze serie hebben besproken, wijst uiteindelijk naar hetzelfde doel: minder tijd, energie en infrastructuuroverhead besteden aan het simpelweg verplaatsen van informatie van de ene plek naar de andere.
De toekomst kan meer afhangen van dataplacement dan van ruwe rekenkracht
Heel lang mat de technologie-industrie vooruitgang vooral aan de hand van ruwe rekenkracht. Snellere processors, grotere accelerators, meer cores en meer parallelisme werden gezien als de belangrijkste signalen van vooruitgang, omdat betere rekenprestaties bij de meeste traditionele workloads meestal het hele systeem verbeterden.
AI dwingt een genuanceerder gesprek af.
Zodra processors snel genoeg worden, verschuift de grotere uitdaging van het kunnen uitvoeren van bewerkingen naar het consequent genoeg voeden van die processors met nuttige data om dure stilstand te voorkomen. Die subtiele verandering beïnvloedt nu bijna elke grote architectuurbeslissing binnen moderne AI-infrastructuur.
Het interessante is dat de oplossing niet langer simpelweg bestaat uit snellere opslagapparaten bouwen of grotere geheugenpools los van elkaar maken. In plaats daarvan richt de industrie zich steeds meer op waar data zich in het systeem bevindt, hoe vaak die beweegt en hoe slim de architectuur onnodig transport kan beperken voordat rekenmiddelen überhaupt betrokken raken.
Daarom is nabijheid zo’n terugkerend thema geworden in elk artikel van deze serie. HBM bracht geheugen fysiek dichter bij de GPU. Storage Class Memory verkleinde de kloof tussen geheugen en opslag. High Bandwidth Flash probeerde NAND actiever te laten deelnemen aan de geheugenhiërarchie. Gedistribueerde opslagsystemen en near-data-processing-architecturen proberen nu te verminderen hoeveel beweging er binnen de infrastructuur zelf plaatsvindt.
Al deze ontwikkelingen reageren op hetzelfde inzicht.
Op AI-schaal wordt data efficiënt verplaatsen bijna net zo belangrijk als de data verwerken zodra die aankomt.
En dat kan uiteindelijk een van de bepalende architectuurverschuivingen van het hele AI-tijdperk worden.
Serie over AI-geheugeninfrastructuur
Dit artikel maakt deel uit van onze lopende serie over hoe AI-infrastructuur de relatie tussen geheugen, opslag en rekenkracht opnieuw vormgeeft. Als je hier in de discussie instapt, bieden de eerdere delen de basis om te begrijpen waarom deze verschuiving plaatsvindt.
Deel één:
NAND verdwijnt niet, maar AI-servers zijn tegenwoordig afhankelijk van meer dan alleen flash
Deel twee:
Wat is High Bandwidth Memory (HBM) en waarom AI ervan afhankelijk is?
Deel drie:
Storage Class Memory uitgelegd: de ontbrekende laag tussen DRAM en NAND
Deel vier:
High Bandwidth Flash: kan NAND zich eindelijk als geheugen gedragen?
Deel vijf:
Waarom DRAM alleen niet langer kan meekomen met AI
Deel zes:
Waarom harde schijven nog steeds belangrijk zijn voor AI-infrastructuur
Deel zeven:
Waarom AI rekenkracht dichter bij opslag brengt
Redactionele noot: Dit artikel maakt deel uit van de lopende serie over AI-infrastructuur en geheugenarchitectuur die wordt gepubliceerd door GetUSB.info. Het artikel is onderzocht en geschreven met AI-ondersteunde redactionele hulp voor structuur en leesbaarheid, en daarna beoordeeld en verfijnd door het redactionele team van GetUSB op technische nauwkeurigheid, samenhang en duidelijkheid.
Over de auteur
Dit artikel is ontwikkeld onder leiding van Matt LeBoff, een langdurige bijdrager aan GetUSB.info met meer dan twintig jaar ervaring in USB-technologie, het gedrag van flashgeheugen en systemen voor dataopslag. Het perspectief dat hier wordt gepresenteerd, weerspiegelt praktische branchekennis en voortdurende analyse van hoe echte systemen presteren onder veranderende workloads, waaronder AI-infrastructuur.