USB-technologie begrijpen voorbij de marketing
Continue analyse van flashgeheugen, USB-technologie en gegevensbeveiliging - helder uitgelegd voor wie echt wil begrijpen wat er gebeurt.
Kernkennisgebieden
Flash-opslag
Hoe NAND werkt, mythen over levensduur, prestatiegedrag en prijstrends.
USB-beveiliging
Kopieerbeveiliging, risico's op datalekken, schrijfbeveiliging en compliancerealiteit.
Data-integriteit
Testtools, usb-sticks met valse capaciteit, corruptieproblemen en verificatiemethoden.
USB-hardware
Wat zit er in een usb-stick, firmwaregedrag en prestatie-afwegingen.
Duplicatiesystemen
Kopiëren bij massaproductie, verificatiemethoden en workflow-ontwerp.
Sectoranalyse
Marktverschuivingen, aanbodbeperkingen, AI-vraag en prijsdynamiek van flashgeheugen.
Uitgelichte analyse
Diepgaande duiken in realistisch USB-gedrag, de economie achter flashgeheugen, controllerkeuzes en beveiligingsafwegingen.
Nieuwste artikelen

Zullen kwantumcomputers USB vervangen? Waarom klassieke computers belangrijk blijven

Zijn M.2 en NVMe hetzelfde? (Hint: dat zijn ze niet)
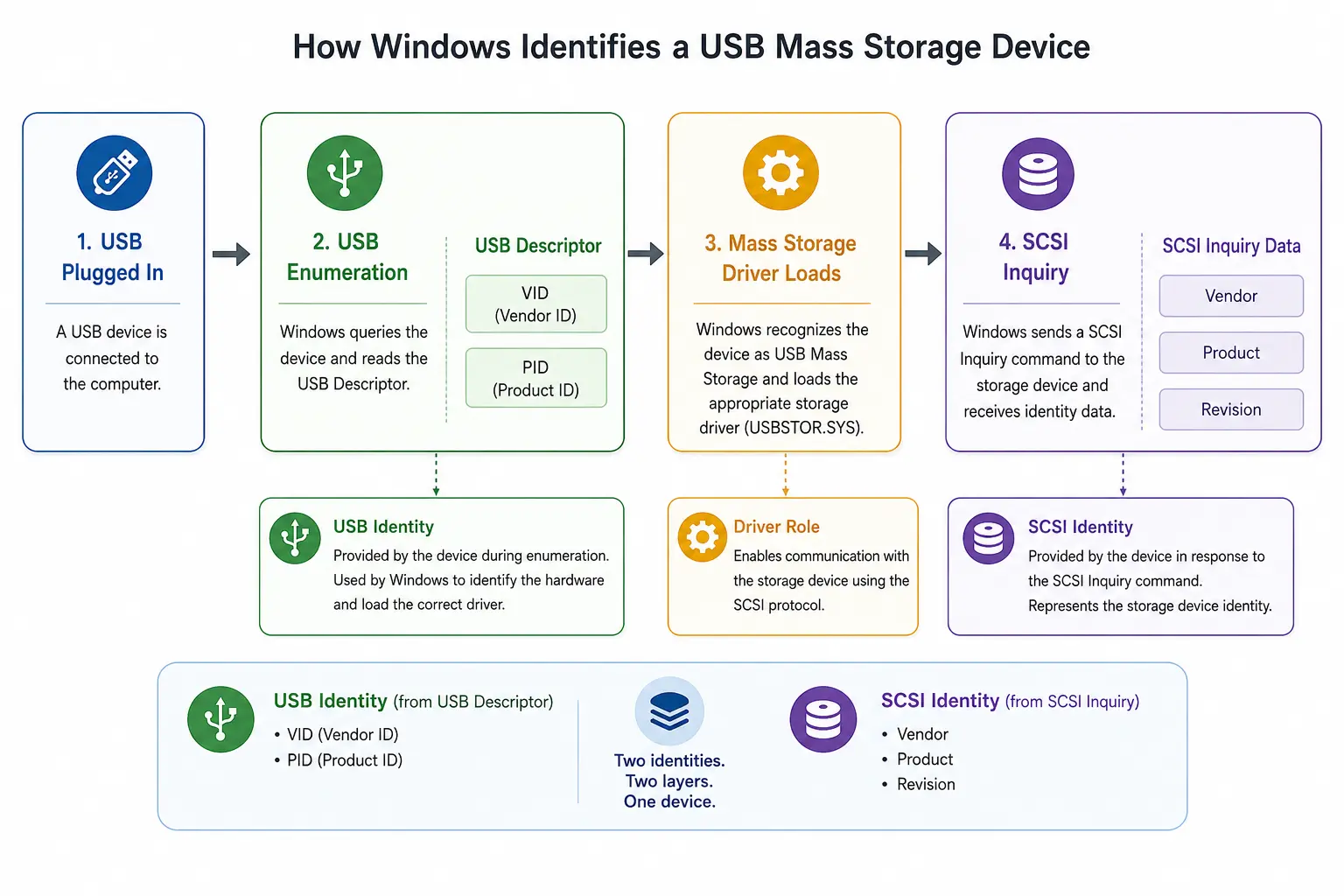
Zo vindt u de VID, PID, SCSI-leverancier en productinformatie van een USB-stick in Windows
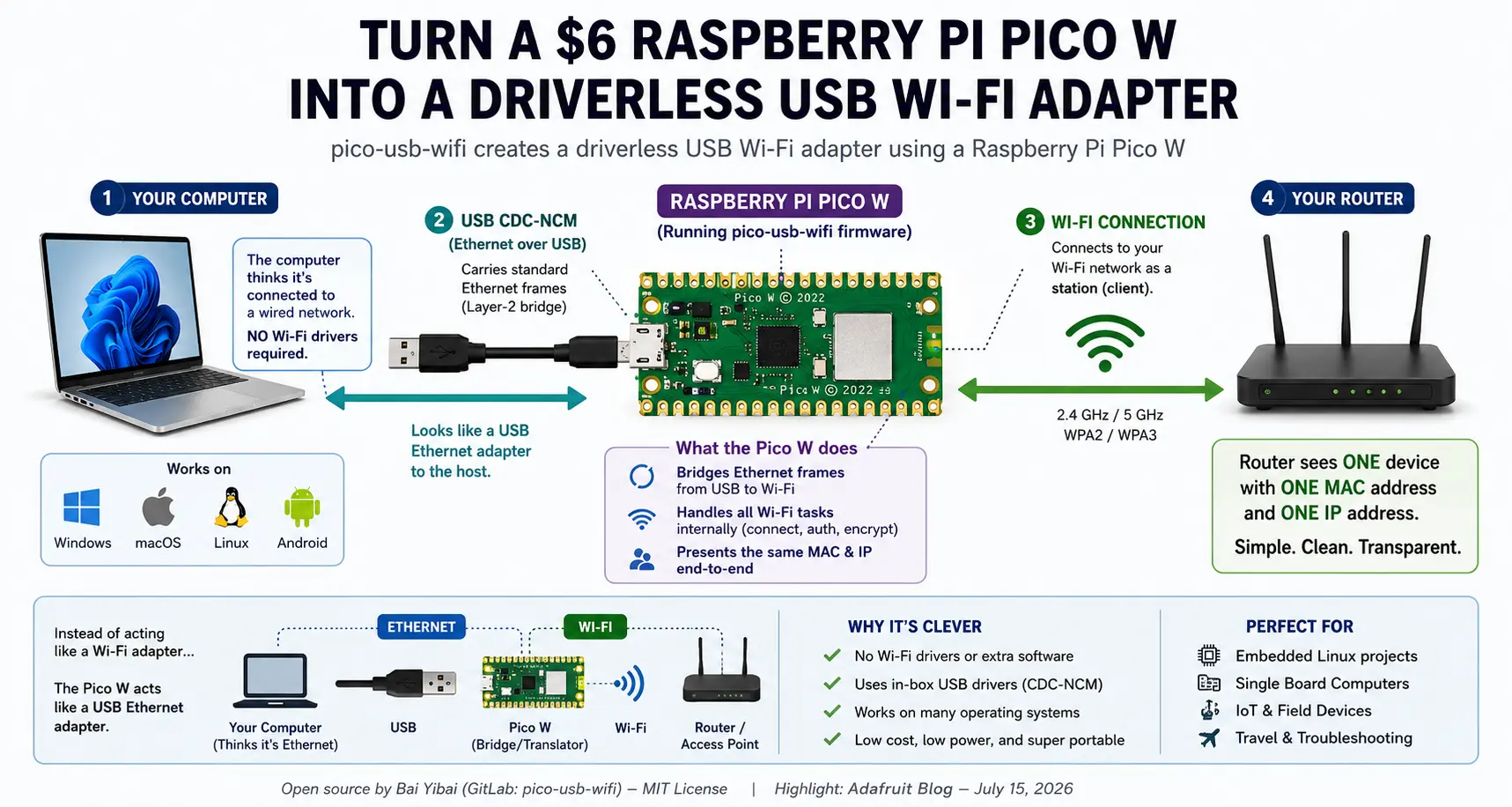
Iemand veranderde een Raspberry Pi Pico W van 6 dollar in een driverloze USB-wifi-adapter. Daarom is dat zo slim
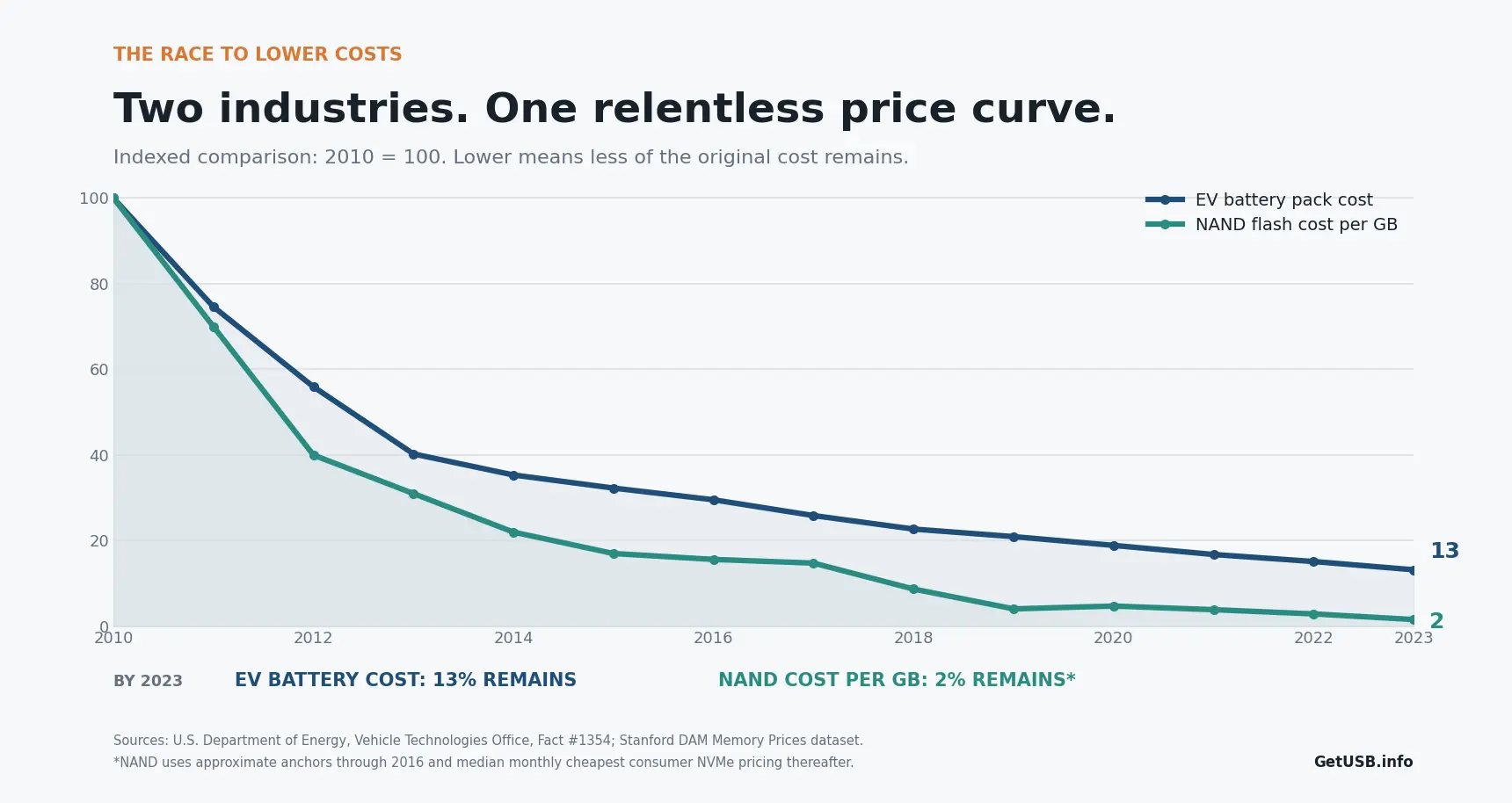
Miljarden om te bouwen. Centen per product
