
NAND verdwijnt niet, maar AI-servers zijn tegenwoordig afhankelijk van meer dan alleen flash
Al meer dan twee decennia kijkt GetUSB naar hoe data zich daadwerkelijk verplaatst, niet alleen hoe het wordt gepresenteerd in marketing. In die tijd hebben we opslag door meerdere cycli zien evolueren, van de afname van draaiende schijven tot de opkomst van flash, en meer recent naar systemen waarin opslag niet langer slechts een passieve component is, maar onderdeel van de infrastructuur zelf.
Wat er nu gebeurt met AI-infrastructuur voelt als opnieuw zo’n overgangsmoment, maar dit keer gedreven door een ander soort druk.
NAND-flash verdwijnt niet, en daar is eigenlijk geen discussie over. Het blijft de basis van moderne opslag en doet dat werk extreem goed. Tegelijkertijd is de vraag naar NAND snel gestegen, grotendeels door AI-workloads die enorme datasets vereisen en daar continu toegang toe nodig hebben. Die vraag begint nu tegen de grenzen van het aanbod aan te lopen op manieren die steeds moeilijker te negeren zijn, of dat nu zichtbaar wordt in prijsdruk, strakkere toewijzingen of simpelweg langere levertijden voor grote implementaties.
Wanneer dit soort onevenwicht zichtbaar wordt, blijft de industrie niet stilzitten en wachten tot alles weer normaliseert. Ze gaat op zoek naar andere manieren om het probleem op te lossen, en daar begint de verschuiving.
De aanname die iedereen maakt
Als je er van buitenaf naar kijkt, lijkt de logica nog steeds vrij redelijk. AI-modellen worden groter, datasets blijven groeien en er wordt meer infrastructuur gebouwd om dat allemaal te ondersteunen, dus de natuurlijke reactie is om meer opslag toe te voegen. Meer SSD’s, meer capaciteit, meer flash in het rack, en het systeem zou moeten kunnen bijbenen.
Die aanpak heeft lange tijd gewerkt en in veel omgevingen doet hij dat nog steeds. De aanname daarachter is echter dat opslag zich onder AI-workloads hetzelfde gedraagt als onder meer traditionele workloads, en daar begint het te schuiven.
Er wordt ook aangenomen dat NAND beschikbaar blijft in de hoeveelheden die nodig zijn en tegen voorspelbare prijzen, iets wat steeds minder zeker wordt naarmate de vraag blijft versnellen.
Waar NAND zijn grenzen begint te laten zien
NAND-flash is uitzonderlijk goed in wat het ontworpen is om te doen. Het biedt compacte, betrouwbare en relatief snelle opslag, en voor algemene computing heeft het een lange lijst problemen opgelost die bij eerdere technologieën bestonden. Zelfs vandaag de dag presteert het voor de meeste workloads precies zoals verwacht.
AI-workloads vragen echter om iets net anders, en dat verschil is belangrijker dan het op het eerste gezicht lijkt.
In plaats van simpelweg data op te slaan en op te halen wanneer nodig, vereisen deze systemen een constante, continue stroom van data naar sterk parallelle compute-resources, vaak op snelheden die moeilijk consistent vol te houden zijn met traditionele opslagarchitecturen. High-performance SSD’s kunnen pieken en grote transactiewachtrijen aan, maar duizenden GPU-cores in realtime voeden is een totaal ander type belasting.
Tegelijkertijd wordt het onderliggende medium – NAND zelf – duurder en in sommige gevallen lastiger om in grote volumes te verkrijgen. De industrie heeft dus met twee vormen van druk tegelijk te maken: de behoefte aan hogere en stabielere datadoorvoer, en de realiteit dat het primaire medium dat deze data levert onder druk staat qua aanbod en kosten.
Die combinatie is wat de huidige verschuiving aandrijft. Niet omdat NAND niet meer werkt, maar omdat alleen daarop vertrouwen niet langer voldoende is om bij te blijven met wat AI-systemen proberen te doen.
De industrie verving NAND niet – ze bouwde eromheen
Wat er nu begint te gebeuren in AI-infrastructuur is geen nette vervanging van NAND, en het is ook geen plotselinge omslag waarbij flash uit het plaatje verdwijnt. Sterker nog, NAND staat nog steeds centraal in deze systemen. Het verschil is dat er niet langer van verwacht wordt dat het alles alleen aankan.
In plaats daarvan bouwt de industrie extra lagen eromheen, elk ontworpen om een specifiek deel van de workload op te vangen waar NAND oorspronkelijk niet voor bedoeld was. In de praktijk betekent dit opnieuw nadenken over hoe data door een systeem beweegt, waar het zich op verschillende momenten bevindt en hoe snel het toegankelijk moet zijn afhankelijk van wat de compute-kant doet.
Hier begint het idee van een geheugenstack vaker op te duiken. Niet als marketingterm, maar als een praktische manier om te beschrijven wat er daadwerkelijk wordt ingezet. In plaats van opslag en geheugen als twee aparte categorieën te behandelen, vervagen AI-systemen die grens en creëren ze meerdere lagen die zich verschillend gedragen afhankelijk van snelheid, kosten en nabijheid tot de processor.
NAND speelt nog steeds een cruciale rol in die stack, vooral voor capaciteit, maar het staat nu naast andere technologieën die specifiek zijn ontworpen om die delen van de workload te verwerken waar latency en bandbreedte belangrijker zijn dan pure opslaggrootte.
Wat er rond NAND wordt gebouwd
Zodra je het systeem op deze manier bekijkt, beginnen de veranderingen logischer te worden. In plaats van NAND te dwingen alles te doen, introduceert de industrie andere lagen die elk een specifiek probleem oplossen. Sommige daarvan zijn al in productie, andere zijn nog in ontwikkeling, maar samen vormen ze de structuur waarop moderne AI-servers beginnen te leunen.
In de volgende reeks artikelen gaan we dieper in op elk van deze lagen afzonderlijk, omdat elke laag meer ruimte verdient dan een overkoepelend artikel kan bieden. Voor nu is het doel om te laten zien hoe de onderdelen in elkaar passen, zodat dit artikel op zichzelf kan staan en tegelijkertijd de basis legt voor de diepere analyses die nog volgen.
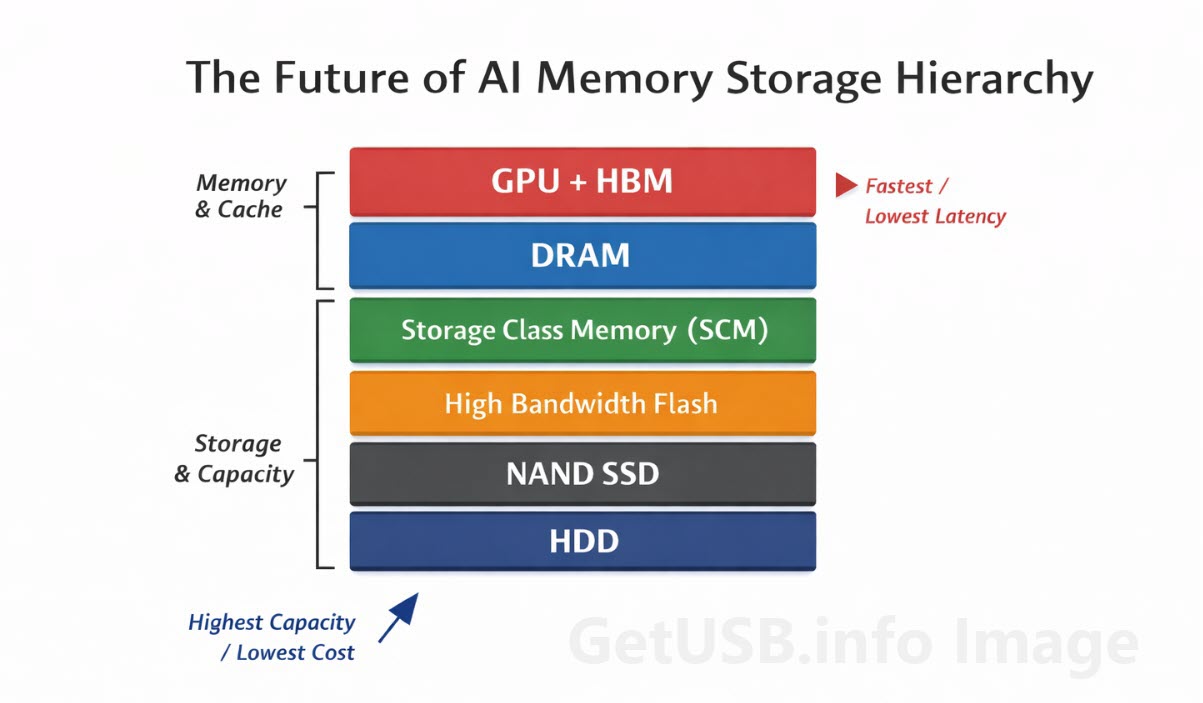
High Bandwidth Memory (HBM)
Helemaal bovenaan de stack, zo dicht mogelijk bij de GPU, zit High Bandwidth Memory, of HBM. Dit is een type gestapelde DRAM dat fysiek dicht bij de processor zit en ontworpen is om extreem hoge datadoorvoer te leveren met zeer lage latency. Het is geen opslagapparaat in de traditionele zin, maar een gespecialiseerde vorm van geheugen die specifiek bedoeld is om moderne GPU’s continu van data te voorzien.
HBM draait niet om capaciteit. Het draait om het bezighouden van de GPU, die in AI-systemen vaak het duurste onderdeel in het rack is. Als die processor op data moet wachten, wordt alles erachter minder efficiënt. HBM lost dat op door bandbreedte en nabijheid te prioriteren boven omvang.
Als je het vergelijkt met een magazijn, is HBM alsof de volgende pallet met goederen al klaarstaat bij het laadperron, uitgepakt en direct klaar om verplaatst te worden. Je vergroot niet de totale voorraad van het magazijn, maar je zorgt er wel voor dat de heftruck nooit hoeft te stoppen en te wachten op de volgende lading.
Voor een diepere vergelijking tussen HBM en opkomende alternatieven hebben we dat hier behandeld: HBM vs HBF: Why the Memory Hierarchy is Being Stretched
Storage Class Memory (SCM)
Net daaronder zit een categorie die een paar jaar geleden praktisch nog niet bestond: opslag die zich meer gedraagt als geheugen.
Storage Class Memory, of SCM, vult de kloof tussen DRAM en NAND. Het heeft niet de snelheid van echt geheugen en ook niet de dichtheid van flash, maar het biedt een balans die het bruikbaar maakt voor workloads die sneller toegang nodig hebben dan NAND kan bieden zonder de volledige kosten van DRAM op schaal te dragen.
In AI-omgevingen helpt deze tussenlaag een deel van de druk op te vangen die anders direct op NAND zou terechtkomen, vooral bij grote werkdatasets die niet netjes binnen traditioneel geheugen passen.
De eenvoudigste magazijnanalogie is om SCM te zien als de staging area tussen de hoofdstellingen van het magazijn en het laadperron. Het magazijn kan alles bevatten, maar het is te traag om telkens opnieuw de gangpaden in te moeten voor elke doos die nodig is. Het laadperron is snel, maar de ruimte is beperkt. SCM is het tussengebied waar de meest waarschijnlijke volgende zendingen al klaarstaan, zodat het proces blijft doorlopen zonder dat je van het laadperron het hele magazijn probeert te maken.
High Bandwidth Flash
Hier begint het echt interessant te worden, want in plaats van een volledig nieuw type geheugen te introduceren, kijkt de industrie ook naar manieren om NAND zelf naar een nieuw niveau te tillen :contentReference[oaicite:0]{index=0}.
High Bandwidth Flash is een poging om flash zich minder als traditionele opslag en meer als een uitbreiding van geheugen te laten gedragen. Het doel is niet om NAND te vervangen, maar om te veranderen hoe het wordt benaderd en geïntegreerd, zodat het efficiënter data kan leveren aan de lagen daarboven.
In zekere zin past NAND zich hier aan de nieuwe omgeving aan in plaats van vervangen te worden, wat aansluit bij wat we in eerdere technologische overgangen hebben gezien. Technologieën verdwijnen zelden van de ene op de andere dag; ze evolueren om relevant te blijven.
DRAM en zijn grenzen
DRAM speelt nog steeds een centrale rol in dit geheel en verdwijnt ook niet. Het blijft het primaire werkgeheugen voor de meeste systemen, inclusief AI-servers, en verwerkt een groot deel van de actieve data die snel toegankelijk moet zijn.
Tegelijkertijd is het niet praktisch om DRAM onbeperkt op te schalen. Kosten, energieverbruik en fysieke beperkingen spelen allemaal een rol, vooral naarmate systemen groter worden. Daardoor kan DRAM alleen niet alle extra vraag van AI-workloads opvangen, wat deels verklaart waarom deze andere lagen worden toegevoegd.
In magazijntermen is DRAM als de vloer van het laadperron zelf. Daar gebeurt het actieve werk, waar dozen worden geopend, gesorteerd en zo snel mogelijk naar de volgende stap gaan. Het probleem is dat je maar een bepaalde hoeveelheid ruimte op het perron kunt bouwen voordat kosten, energie en indeling niet meer logisch zijn. Op een gegeven moment heb je nog steeds staging zones dichtbij nodig en diepere opslag erachter, omdat alles alleen op het perron doen duur en inefficiënt wordt.
De stille terugkeer van harde schijven
Ondanks alle focus op snelle geheugenlagen en flash maken traditionele harde schijven nog steeds deel uit van het geheel, vooral onderaan de stack waar kosten per terabyte belangrijker zijn dan snelheid.
AI-systemen genereren en gebruiken enorme hoeveelheden data, en niet alles hoeft in high-performance opslag te staan. Trainingsdatasets, archieven en minder vaak geraadpleegde informatie hebben nog steeds een plek nodig, en daarvoor blijven harde schijven een van de meest economische oplossingen.
Ze concurreren niet met NAND of geheugen op prestaties, maar ze verlagen de totale druk op die lagen door bulkopslag voor hun rekening te nemen.
Compute dichter bij opslag brengen
Een andere verschuiving die aandacht krijgt, is het idee om de afstand die data moet afleggen te verkleinen. In plaats van voortdurend grote hoeveelheden data heen en weer te verplaatsen tussen opslag en compute, beginnen sommige architecturen verwerking dichter bij de data zelf te brengen.
Deze aanpak elimineert de behoefte aan snelle opslag of geheugen niet, maar verandert wel de balans. Door bepaalde bewerkingen dichter bij de data uit te voeren, kunnen systemen knelpunten verminderen en de algehele efficiëntie verbeteren zonder volledig afhankelijk te zijn van snellere media.
De rol van AI-context (KV-cache)
Een van de minder zichtbare factoren die dit alles aandrijven, is de hoeveelheid tijdelijke data die AI-modellen genereren tijdens het draaien. Dit wordt vaak context of KV-cache genoemd en vertegenwoordigt de werkstatus van een model terwijl het input verwerkt en output genereert.
Die data past niet altijd netjes in traditioneel geheugen, vooral niet op schaal, wat verklaart waarom systemen opslag beginnen te behandelen als een verlengstuk van geheugen in plaats van een volledig aparte laag. Het is nog een voorbeeld van hoe de grenzen tussen deze categorieën steeds verder vervagen.
De magazijnanalogie werkt hier ook. KV-cache is als de actieve picklijst en het klembord voor alles wat op dat moment wordt gepickt, gesorteerd en verzonden. Het is niet de volledige voorraad en ook geen lange termijn opslag, maar als die live werkset te groot of moeilijk toegankelijk wordt, vertraagt de hele operatie omdat niemand meer weet wat net is gepakt, wat de volgende stap is of waar de huidige order zich bevindt.
De nieuwe AI-geheugenstack
Als je een stap terug doet en naar het geheel kijkt, begint het meer te lijken op een gelaagde structuur dan op een simpele hiërarchie.
Bovenaan heb je de GPU samen met HBM die directe, snelle operaties afhandelt. Daarachter zit DRAM, dat actieve workloads beheert die snelle toegang nodig hebben maar niet direct op de processor hoeven te zitten. Daaronder helpen opkomende lagen zoals SCM en high-bandwidth flash de kloof tussen geheugen en opslag te overbruggen, waardoor extra capaciteit beschikbaar komt zonder al te veel prestatieverlies.
Nog verder naar beneden blijft traditionele NAND verantwoordelijk voor grootschalige opslag, terwijl harde schijven de rol van langdurige, kostenefficiënte dataopslag op zich nemen.
Als je het geheel als een magazijn voorstelt, wordt de structuur duidelijker. HBM is de pallet bij het laadperron, DRAM is de vloer waar het werk gebeurt, SCM is de staging area daarachter, NAND zijn de hoofdstellingen en harde schijven zijn de diepe opslag achterin waar kosten en capaciteit belangrijker zijn dan snelheid. Het systeem werkt omdat elke laag een rol heeft en omdat niemand verwacht dat de achterkant van het magazijn het werk van het laadperron doet.
Elke laag heeft zijn functie, en samen vormen ze een systeem dat beter aansluit bij de eisen van AI dan welke afzonderlijke technologie dan ook.
Wat dit betekent voor de toekomst
De conclusie hier is niet dat NAND wordt vervangen, of dat één nieuwe technologie het overneemt. Wat er gebeurt is geleidelijker en op veel manieren interessanter.
De industrie erkent dat geen enkele laag alles kan afhandelen, zeker niet onder de druk van AI. In plaats van één technologie tot het uiterste te rekken, wordt er een systeem gebouwd waarin meerdere lagen samenwerken, elk geoptimaliseerd voor een specifieke rol.
Die verschuiving verandert hoe we naar opslag kijken. Het gaat niet langer alleen om capaciteit of zelfs ruwe snelheid, maar om hoe data door het systeem beweegt en hoe efficiënt elke laag de laag daarboven ondersteunt.
En terwijl deze architecturen zich blijven ontwikkelen, blijft NAND een cruciaal onderdeel van het geheel – alleen niet meer het enige.
Labels:AI memory stack, AI-infrastructuur, HBM, NAND-flash, storage class memory